AutoScratch: ML-Optimized Cache Management for Inference-Oriented GPUs
{kind=link}
Abstract
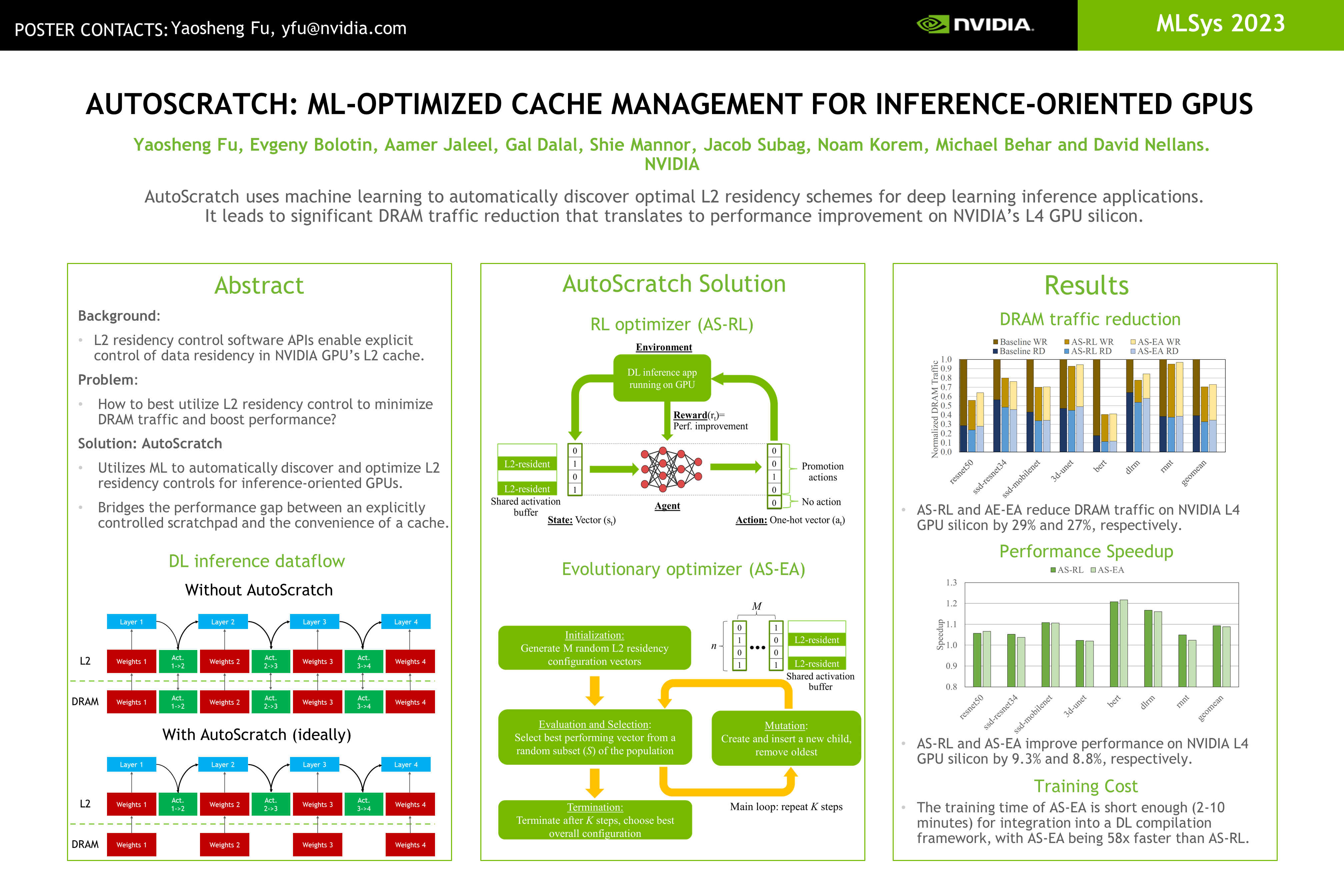
Taking advantage of the L2 residency control mechanism introduced with NVIDIA's Ampere GPUs, we propose a Machine Learning (ML) based framework called AutoScratch to automatically discover and optimize the L2 residency for inference-oriented GPUs, effectively removing any human involvement from the optimization loop. AutoScratch bridges the gap between the performance of an explicitly controlled scratchpad memory and the convenience of a hardware-controlled cache. We develop two versions of AutoScratch, AutoScratch-RL harnessing reinforcement learning (RL) and AutoScratch-EA leveraging a state-of-the-art evolutionary algorithm (EA). We integrate AutoScratch with NVIDIA's TensorRT framework to fully automate the optimization pipeline for arbitrary DL inference applications. We evaluate AutoScratch on NVIDIA's L4 GPU silicon using MLPerf inference workloads and show that AutoScratch reduces off-chip DRAM traffic by 29% and improves the overall performance by 9% (up to 22%).