Registration Desk Tue 6 Jun 07:30 a.m.
Poster: Measurement and Analysis Tue 6 Jun 09:00 a.m.
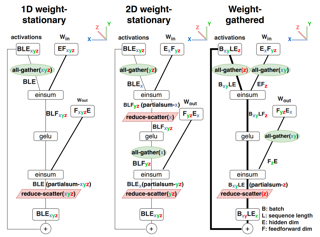
Abstract
We study the problem of efficient generative inference for Transformer models, in one of its most challenging settings: large deep models, with tight latency targets and long sequence lengths. Better understanding of the engineering tradeoffs for inference for large Transformer-based models is important as use cases of these models are growing rapidly throughout application areas. We develop a simple analytical model for inference efficiency to select the best multi-dimensional partitioning techniques optimized for TPU v4 slices based on the application requirements. We combine these with a suite of low-level optimizations to achieve a new Pareto frontier on the latency and model FLOPS utilization (MFU) tradeoffs on 500B+ parameter models that outperforms theFasterTransformer suite of benchmarks. We further show that with appropriate partitioning, the lower memory requirements of multiquery attention (i.e. multiple query heads share single key/value head) enables scaling up to32×larger context lengths. Finally, we achieve a low-batch-size latency of 29ms per token during generation (using int8 weight quantization) and a 76% MFU during large-batch-size processing of input tokens, while supporting a long 2048-token context length on the PaLM 540B parameter model.
Abstract
Profiling is a standard practice used to investigate the efficiency of software and hardware operation at runtime and is a crucial part of proving new concepts, debugging problems, and optimizing performance. However, most machine learning (ML) developers find profiling secondary to their goal of improving model accuracy or just too difficult (especially with existing ML tools). As a result, profiling is frequently an afterthought, and so many ML developers rely on opaque metrics such as iteration time and GPU utilization which give little insight into why ML training may be slow. This leads developers to spend excessive time investigating performance issues. In this work, we aim to provide better tools to the large group of ML developers who currently do not profile their deep neural network (DNN) training workloads or are not happy with existing tools. To help ML developers investigate and understand time-use in DNN training, we propose Hotline, a novel profiler designed specifically for runtime bottleneck identification. Hotline is the first profiler to automatically annotate a standard data format for program runtime traces with DNN concepts that most ML developers are familiar with, i.e. the DNN training loop and model architecture. Hotline does so without modifying DNN libraries …
Abstract
To deploy compute-intensive neural networks on resource-constrained edge systems, developers use model optimization techniques that reduce model size and computational cost. Existing optimization tools are application-agnostic -- they optimize model parameters solely in view of the neural network accuracy -- and can thus miss optimization opportunities. We propose ApproxCaliper, the first programmable framework for application-aware neural network optimization. By incorporating application-specific goals, ApproxCaliper facilitates more aggressive optimization of the neural networks compared to application-agnostic techniques. We perform experiments on five different neural networks used in two real-world robotics systems: a commercial agriculture robot and a simulation of an autonomous electric cart. Compared to Learning Rate Rewinding (LRR), a state-of-the-art structured pruning tool used in an application-agnostic setting, ApproxCaliper achieves 5.3x higher speedup and 2.9x lower GPU resource utilization, and 36x and 6.1x additional model size reduction, respectively.
Invited Talk: Alexander Rush
Modern NLP runs on Transformers. Large language models are possible because of system successes in making Transformers bigger, faster, and longer-range. However, 5 years after the advent of BERT and GPT, it is still an open question whether the central routing component of Transformers, Self-Attention, is central to their success in pretraining, or whether it is worth developing large-scale systems for alternative approaches. Inspired by an off-hand wager on this topic https://www.isattentionallyouneed.com, this talk will be an overview of recent work exploring the use of alternative approaches for routing in large-scale NLP architectures. After giving background on the best practices and context of modern NLP, I will describe alternative approaches, primarily focusing on static methods based on state-space models (SSMs) and long-range convolutions. I will conclude by discussing the current empirical results and theoretical properties of these models, as well as paths for their future systems development as competitive technologies.
Bio :
Poster: Parallel and Distributed Systems 2: Communication Tue 6 Jun 01:30 p.m.
Abstract
Data-parallel distributed training (DDT) is the de facto way to accelerate deep learning on multiple GPUs.In DDT, communication for gradient synchronization is the major efficiency bottleneck.Many gradient compression (GC) algorithms have been proposed to address this communication bottleneck by reducing the amount of communicated data.Unfortunately, it has been observed that GC only achieves moderate performance improvement in DDT, or even harms the performance.In this paper, we argue that the current way of deploying GC in a layer-wise fashion reduces communication time at the cost of non-negligible compression overheads.To address this problem, we propose Cupcake, a compression optimizer to fully unleash GC algorithms' advantages in accelerating DDT. It applies GC algorithms in a fusion fashion and determines the provably optimal fusion strategy to maximize the training throughput of compression-enabled DDT jobs.Experimental evaluations show that GC algorithms with Cupcake can achieve up to 2.03x speedup in training throughput over training without GC, and up to 1.79x speedup over the state-of-the-art approaches of applying GC to DDT in a layer-wise fashion.
Abstract
Training and inference with graph neural networks (GNNs) on massive graphs in a distributed environment has been actively studied since the inception of GNNs, owing to the widespread use and success of GNNs in applications such as recommendation systems and financial forensics. This paper is concerned with minibatch training and inference with GNNs in distributed settings, where the necessary partitioning of vertex features across distributed storage causes feature communication to become a major bottleneck that hampers scalability.To significantly reduce the communication volume without compromising prediction accuracy, we propose a policy for caching data associated with frequently accessed vertices in remote partitions. The proposed policy is based on an analysis of vertex-wise inclusion probabilities (VIP) during multi-hop neighborhood sampling, which may expand the neighborhood far beyond the partition boundary of the graph. The VIP analysis not only enables the elimination of the communication bottleneck, but also offers a means to organize in-memory data by prioritizing GPU storage for the most frequently accessed vertex features. We present SALIENT++, which extends the prior state-of-the-art SALIENT system to work with partitioned feature data and leverages the VIP-driven caching policy. SALIENT++ retains the local training efficiency and scalability of SALIENT by using a deep pipeline …
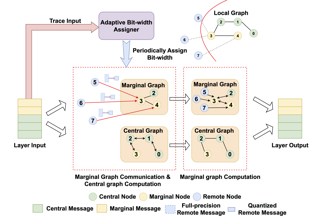
Abstract
Distributed full-graph training of Graph Neural Networks (GNNs) over large graphs is bandwidth-demanding and time-consuming. Frequent exchanges of node features, embeddings and embedding gradients (all referred to as messages) across devices bring significant communication overhead for nodes with remote neighbors on other devices (marginal nodes) and unnecessary waiting time for nodes without remote neighbors (central nodes) in the training graph. This paper proposes an efficient GNN training system, AdaQP, to expedite distributed full-graph GNN training. We stochastically quantize messages transferred across devices to lower-precision integers for communication traffic reduction and advocate communication-computation parallelization between marginal nodes and central nodes. We provide theoretical analysis to prove fast training convergence (at the rate of O(T^{-1}) with T being the total number of training epochs) and design an adaptive quantization bit-width assignment scheme for each message based on the analysis, targeting a good trade-off between training convergence and efficiency. Extensive experiments on mainstream graph datasets show that AdaQP substantially improves distributed full-graph training's throughput (up to 3.01 X) with negligible accuracy drop (at most 0.30%) or even accuracy improvement (up to 0.19%) in most cases, showing significant advantages over the state-of-the-art works.
Abstract
We study a novel and important communication pattern in large-scale model-parallel deep learning (DL), which we call cross-mesh resharding. This pattern emerges when the two paradigms of model parallelism – intra-operator and inter-operator parallelism – are combined to support large models on large clusters. In cross-mesh resharding, a sharded tensor needs to be sent from a source device mesh to a destination device mesh, on which the tensor may be distributed with the same or different layouts. We formalize this as a many-to-many multicast communication problem, and show that existing approaches either are sub-optimal or do not generalize to different network topologies or tensor layouts, which result from different model architectures and parallelism strategies. We then propose two contributions to address cross-mesh resharding: an efficient broadcast-based communication system, and an “overlapping-friendly" pipeline schedule. On microbenchmarks, our overall system outperforms existing ones by up to 10x across various tensor and mesh layouts. On end-to-end training of two large models, GPT-3 and U-Transformer, we improve throughput by 10% and 50%, respectively.
Poster: Federated Learning Tue 6 Jun 03:20 p.m.
Abstract
While the quality of machine learning services largely relies on the volume of training data, data regulations such as the General Data Protection Regulation (GDPR) impose stringent requirements on data transfer. Federated learning has emerged as a popular approach for enabling collaborative machine learning without sharing raw data. To facilitate the rapid development of federated learning, efficient and user-friendly federated learning systems are essential. Despite many existing federated learning systems designed for deep learning, tree-based federated learning systems have not been well exploited. This paper presents a tree-based federated learning system under a histogram-sharing scheme, named FedTree, that supports both horizontal and vertical federated training of GBDTs with configurable privacy protection techniques. Our extensive experiments show that FedTree achieves competitive accuracy to centralized training while incurring much less computational cost than the other generic federated learning systems.

Abstract
Cross-device federated learning (FL) has been well-studied from algorithmic, system scalability, and training speed perspectives. Nonetheless, moving from centralized training to cross-device FL for millions or billions of devices presents many risks, including performance loss, developer inertia, poor user experience, and unexpected application failures. In addition, the corresponding infrastructure, development costs, and return on investment are difficult to estimate. In this paper, we present a device-cloud collaborative FL platform that integrates with an existing machine learning platform, providing tools to measure real-world constraints, assess infrastructure capabilities, evaluate model training performance, and estimate system resource requirements to responsibly bring FL into production. We also present a decision workflow that leverages the FL-integrated platform to comprehensively evaluate the trade-offs of cross-device FL and share our empirical evaluations of business-critical machine learning applications that impact hundreds of millions of users.
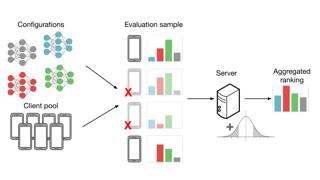
Abstract
Hyperparameter tuning is critical to the success of federated learning applications. Unfortunately, appropriately selecting hyperparameters is challenging in federated networks, as issues of scale, privacy, and heterogeneity introduce noise in the tuning process and make it difficult to faithfully evaluate the performance of various hyperparameters. In this work we perform the first systematic study on the effect of noisy evaluation in federated hyperparameter tuning. We first identify and rigorously explore key sources of noise, including client subsampling, data and systems heterogeneity, and data privacy. Surprisingly, our results indicate that even small amounts of noise can have a significant impact on tuning methods—reducing the performance of state-of-the-art approaches to that of naive baselines. To address noisy evaluation in such scenarios, we propose a simple and effective approach that leverages public proxy data to boost evaluation signal. Our work establishes general challenges, baselines, and best practices for future work in federated hyperparameter tuning.
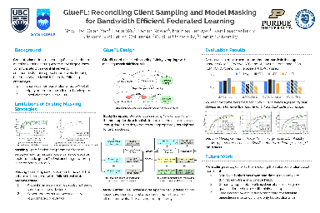
Abstract
Federated learning (FL) is an effective technique to directly involve edge devices in machine learning training while preserving client privacy. However, the substantial communication overhead of FL makes training challenging when edge devices have limited network bandwidth. Existing work to optimize FL bandwidth overlooks downstream transmission and does not account for FL client sampling. In this paper we propose GlueFL, a framework that incorporates new client sampling and model compression algorithms to mitigate low download bandwidths of FL clients. GlueFL prioritizes recently used clients and bounds the number of changed positions in compression masks in each round. Across three popular FL datasets and three state-of-the-art strategies, GlueFL reduces downstream client bandwidth by 27% on average and reduces training time by 29% on average.
Poster: ML for Systems Tue 6 Jun 04:40 p.m.
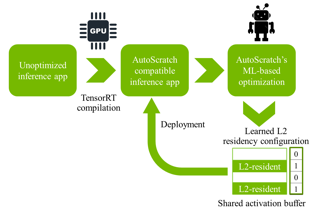
Abstract
Taking advantage of the L2 residency control mechanism introduced with NVIDIA's Ampere GPUs, we propose a Machine Learning (ML) based framework called AutoScratch to automatically discover and optimize the L2 residency for inference-oriented GPUs, effectively removing any human involvement from the optimization loop. AutoScratch bridges the gap between the performance of an explicitly controlled scratchpad memory and the convenience of a hardware-controlled cache. We develop two versions of AutoScratch, AutoScratch-RL harnessing reinforcement learning (RL) and AutoScratch-EA leveraging a state-of-the-art evolutionary algorithm (EA). We integrate AutoScratch with NVIDIA's TensorRT framework to fully automate the optimization pipeline for arbitrary DL inference applications. We evaluate AutoScratch on NVIDIA's L4 GPU silicon using MLPerf inference workloads and show that AutoScratch reduces off-chip DRAM traffic by 29% and improves the overall performance by 9% (up to 22%).

Abstract
Careful placement of a distributed computational application within a target device cluster is critical for achieving low application completion time. The problem is challenging due to its NP-hardness and combinatorial nature. In recent years, learning-based approaches have been proposed to learn a placement policy that can be applied to unseen applications, motivated by the problem of placing a neural network across cloud servers. These approaches, however, generally assume the device cluster is fixed, which is not the case in mobile or edge computing settings, where heterogeneous devices move in and out of range for a particular application. To address the challenge of scaling to different-sized device clusters and adapting to the addition of new devices, we propose a new learning approach called GiPH, which learns policies that generalize to dynamic device clusters via a novel graph representation gpNet that efficiently encodes the information needed for choosing a good placement, and a scalable graph neural network (GNN) that learns a summary of the gpNet information. GiPH turns the placement problem into that of finding a sequence of placement improvements, learning a policy for selecting this sequence that scales to problems of arbitrary size. We evaluate GiPH with a wide range of …
Abstract
Detecting parallelizable code regions is a challenging task, even for experienced developers. Numerous recent studies have explored the use of machine learning for code analysis and program synthesis, including parallelization, in light of the success of machine learning in natural language processing. However, applying machine learning techniques to parallelism detection presents several challenges, such as the lack of an adequate dataset for training, an effective code representation with rich information, and a suitable machine learning model to learn the latent features of code for diverse analyses. To address these challenges, we propose a novel graph-based learning approach called Graph2Par that utilizes a heterogeneous augmented abstract syntax tree (Augmented-AST) representation for code. The proposed approach primarily focused on loop-level parallelization with OpenMP. Moreover, we create an OMP_Serial dataset with 18598 parallelizable and 13972 non-parallelizable loops to train the machine learning models. Our results show that our proposed approach achieves the accuracy of parallelizable code region detection with 85\% accuracy and outperforms the state-of-the-art token-based machine learning approach. These results indicate that our approach is competitive with state-of-the-art tools and capable of handling loops with complex structures that other tools may overlook.
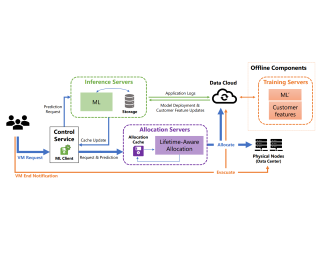
Abstract
The emergence of machine learning technology has motivated the use of ML-based predictors in computer systems to improve their efficiency and robustness. However, there are still numerous algorithmic and systems challenges in effectively utilizing ML models in large-scale resource management services that require high throughput and response latency of milliseconds. In this paper, we describe the design and implementation of a VM allocation service that uses ML predictions of the VM lifetime to improve packing efficiencies. We design lifetime-aware placement algorithms that are provably robust to prediction errors and demonstrate their merits in extensive real-trace simulations. We significantly upgraded the VM allocation infrastructure of Microsoft Azure to support such algorithms that require ML inference in the critical path. A robust version of our algorithms has been recently deployed in production, and obtains efficiency improvements expected from simulations.